磁盘和文件
1 内存和硬盘
不论数据库什么时候使用数据,数据必须在内存中,访问这些数据相对较快,但是一旦数据量变得很大,将所有数据装进内存将变得不可能。磁盘配用来便宜的储存数据库的数据,但无论何时访问数据或写入新数据,它们都会产生巨大的成本。
2 文件、页面、记录
关系型数据库最基本的单位是记录(行)。这些记录被组织成关系(表),他们可以被修改,删除或者在内存中创建。
对磁盘来说基本的单位是页,是从磁盘到内存传输的最小单位,反之亦然。为了以与磁盘兼容的格式表示关系数据库,每个关系都存储在自己的文件中,其记录被组织到文件中的页面中。基于关系的模式和访问模式,数据库将确定:(1)使用的文件类型,(2)文件中页面的组织方式,(3)每个页面上记录的组织方式,以及(4)每个记录的格式。
3 选择文件类型
文件有两种主要类型:堆文件和排序文件。对于每个关系,数据库根据关系访问模式的I/O成本选择要使用的文件类型。1个I/O相当于从磁盘读取1页或向磁盘写入1页,并且基于其访问模式中的插入、删除和扫描操作,为每种文件类型进行I/O计算。选择产生较少I/O成本的文件类型。
4 堆文件
堆文件是一种文件类型,没有页面或页面上记录的特定顺序,它有两个主要实现:
4.1 链表实现
在链表实现中,每一个数据页包含一个记录,一个自由空间追踪器和一个指针指向前一个界面或者后一个界面。有一个header pages被用作文件的开始,并且把界面分为满页和自由页。当空间被需要的时候,空页被分配并加到自由页的部分。当自由页的数据满了就把自由页加到满页部分的前头。因为我们加在前面,所以不需要穿过整个满页去添加它。另一种方法是在标题页中保持指向该列表末尾的指针。我们使用的实现的细节对于本课程并不重要。
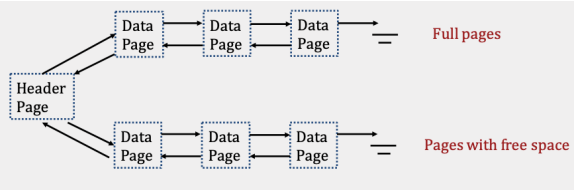
4.2 页面文件实现
页面文件实现和链表的实现不同之处在于使用了header pages的链表。每个header pages包含一个指针指向下一个header pages。每个header pages包含一个指针(字节偏移)到下一个header pages,它全部包含了一个指向数据页的指着和一堆指向空闲数据页的指针。因为我们的头页面储存了全部的数据页面,数据页面不用在储存相邻的页面。

与链表相比,页面目录的主要优点是插入记录通常更快。要在链表实现中找到具有足够空间的页面,可能需要读取标题页面和空闲部分中的每个页面。相反,页面目录实现最多只需要读取所有标题页,因为它们包含关于文件中每个数据页上剩余空间的信息。
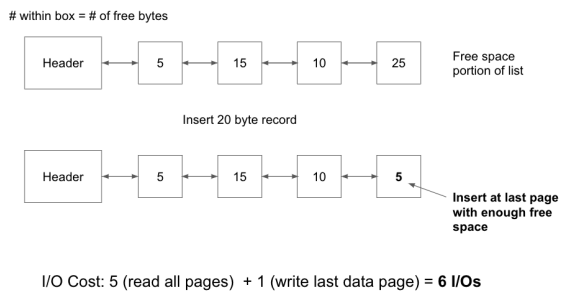
为了强调这一点,请考虑以下示例,其中堆文件被实现为链接列表和页面目录。每个页面为30字节,一个20字节的记录被插入到文件中:
链表
页面目录
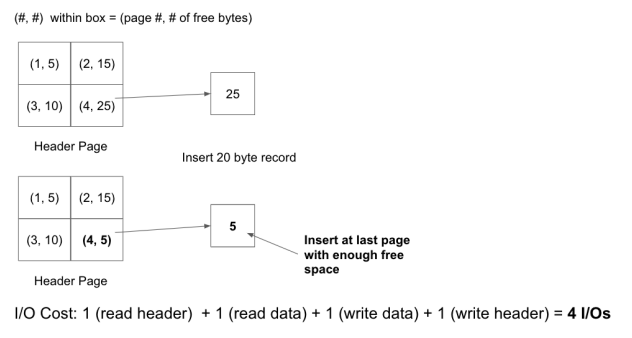
这只是一个很小的例子,随着页面数量的增加,这种情况会导致在链接列表中插入比在页面目录中插入要昂贵得多。
无论使用何种实现,堆文件都比排序文件(如下所述)提供更快的插入,因为记录可以添加到具有空闲空间的任何页面,而找到具有足够空闲空间的页面通常非常便宜。但是,在堆文件中搜索记录每次都需要完全扫描。必须查看每个页面上的每个记录,因为记录是无序的,导致每次搜索操作的线性成本为N个I/O。我们将看到,排序后的文件在搜索记录时会更好。
排序的文件
排序文件是一种文件类型,其中页面排序,每个页面中的记录按键排序。
这些文件使用页面目录实现,并根据记录的排序方式对数据页面进行排序。查找排序的文件需要logn的IO。其中N为界面的数量,因为二分搜索可以用来查找包含记录的界面。同时,在平均情况下,插入需要logN+N个I/O,因为需要二分搜索才能找到要写入的页面,并且插入的记录可能会导致所有后续记录被推回一个。平均而言,N/2页将需要被推回,并且这涉及对这些页中的每一页的读和写IO,这导致N个I/O项。
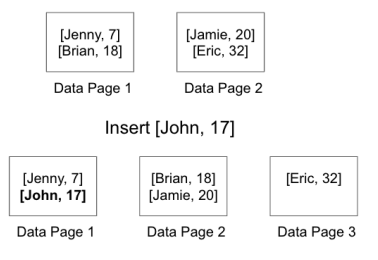
下面的例子说明了最坏的情况。每个数据页最多可存储2条记录,因此在数据页1中插入一条记录需要对随后的所有页进行读写,因为其余记录需要被推回。
6 Header Pages 计数的注意事项
在计算操作成本I/O时,一个常见的混淆区域是是否将访问文件头页的成本包括在内。对于本课程中的所有问题,当问题中没有提供底层文件实现时,您应该忽略与读/写文件头页相关的I/O成本。另一方面,当问题中提供了特定的文件实现(即,使用链接列表或页面目录实现的堆文件)时,您必须包括与读取/写入文件头页相关的I/O成本。
7 记录类型
记录类型完全由关系的模式决定,有两种类型:固定长度记录(FLR)和可变长度记录(VLR)。FLR仅包含固定长度字段(整数、布尔值、日期等),具有相同模式的FLR由相同数量的字节组成。同时,VLR包含固定长度和可变长度字段(如varchar),导致相同模式的每个VLR具有潜在不同的字节数。VLR在可变长度字段之前存储所有固定长度字段,并使用包含指向可变长度字段结尾的指针的记录头。
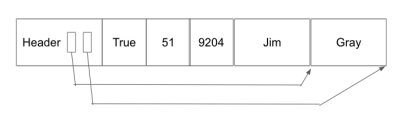
无论格式如何,每个记录都可以通过其记录id唯一标识-[第#页,第#个记录在这一页]。
8 页面类型
8.1固定长度记录的页面
包含FLR的页面始终使用Header Page来存储当前页面上的记录数。如果页面已打包,则记录之间没有间隙。这使得插入变得容易,因为我们可以使用现有记录的数量和每条记录的长度来计算页面中的下一个可用位置。计算此值后,我们将在计算的偏移量处插入记录。删除稍微复杂一些,因为它需要将删除记录之后的所有记录移到页面顶部一个位置,以保持页面压缩。如果页面被解包,页面标题通常会存储一个额外的位图,该位图将页面分成多个插槽,并跟踪打开或占用的插槽。
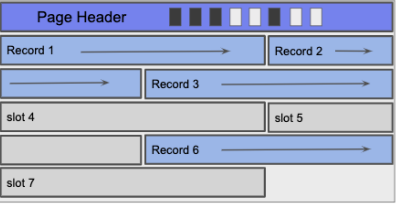
使用位图,插入包括找到第一个打开位,在相应的槽中设置新记录,然后为该槽设置位。删除时,我们清除已删除记录的相应位,以便将来的插入可以覆盖该插槽。
8.2都是机翻的,有空再看看
8.2具有可变长度记录的页面
可变长度记录和固定长度记录之间的主要区别在于,我们不再保证每个记录的大小。为了解决这个问题,每个页面都使用一个页面页脚来维护插槽目录跟踪插槽计数、空闲空间指针和条目。页脚从页面底部而不是顶部开始,这样插入记录时插槽目录就有增长空间。
插槽计数跟踪插槽总数。这包括填充和空插槽。空闲空间指针指向页面内的下一个空闲位置。插槽目录中的每个条目由一个[记录指针,记录长度]对组成。
如果页面被解包,删除涉及在槽目录中查找记录的条目,并将记录指针和记录长度设置为空。
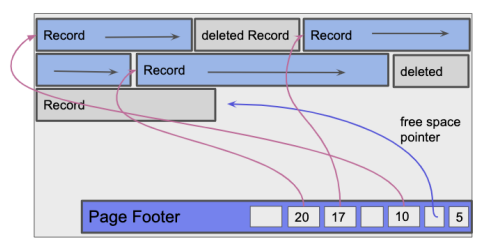
对于将来的插入,记录将在空闲空间指针处插入页面,并在任何可用的空条目中设置新的[pointer,length]对。在没有空条目的情况下,将向该记录的槽目录添加新条目。时隙计数用于确定新时隙条目应添加到哪个偏移,然后时隙计数递增。定期将记录重新组织为压缩状态,删除已删除的记录,以便为将来的插入腾出空间。
如果页面已打包,则删除涉及将插槽目录中的记录条目设置为空。此外,删除记录后的记录必须向页面顶部移动一个位置,相应的槽目录条目必须向页面底部移动一个。请注意,我们只是在删除记录的页面内移动记录。我们不会为文件跨页面重新打包记录。对于插入,记录在空闲空间指针处插入,如果所有插槽都已满,则每次都会添加一个新条目。